2024-11-09 01:34:06 2
從2024年1-7月,央國企採購大模型專案數量已超過950個,且均勻佈局在智算中心、大模型預訓練、Agent和行業應用等多個方向。而除了政策影響,央國企紛紛落地大模型的背後還有哪些推動因素?
最高191億元,最低不到1萬元。大模型狂飆兩年,國內“AGI陣隊”已然形成。同步進行著的,還有央國企的大模型專案建設。
8月6日,神州數碼集團釋出公告表示,子公司神州鯤泰中標《中國移動2024年至2025年新型智算中心採購(標包1)》,投標報價約191億元,中標份額10.53%。2024年7月,湖南省委黨校湖南行政學院釋出招標資訊,採購數字機器人服務,報價9000元。


一個是智算中心採購,一個是數字機器人服務;可以看到的是,如今在央國企內部,大模型專案建設已行至中途。甚至毫不誇張地說,在大模型浪潮席捲而來的今天,央國企正在成為一股先行力量,推動著國內大部分的AI大模型落地專案。
據不完全統計,從2024年1-7月,央國企採購大模型專案數量已超過950個,且均勻佈局在智算中心、大模型預訓練、Agent和行業應用等多個方向。
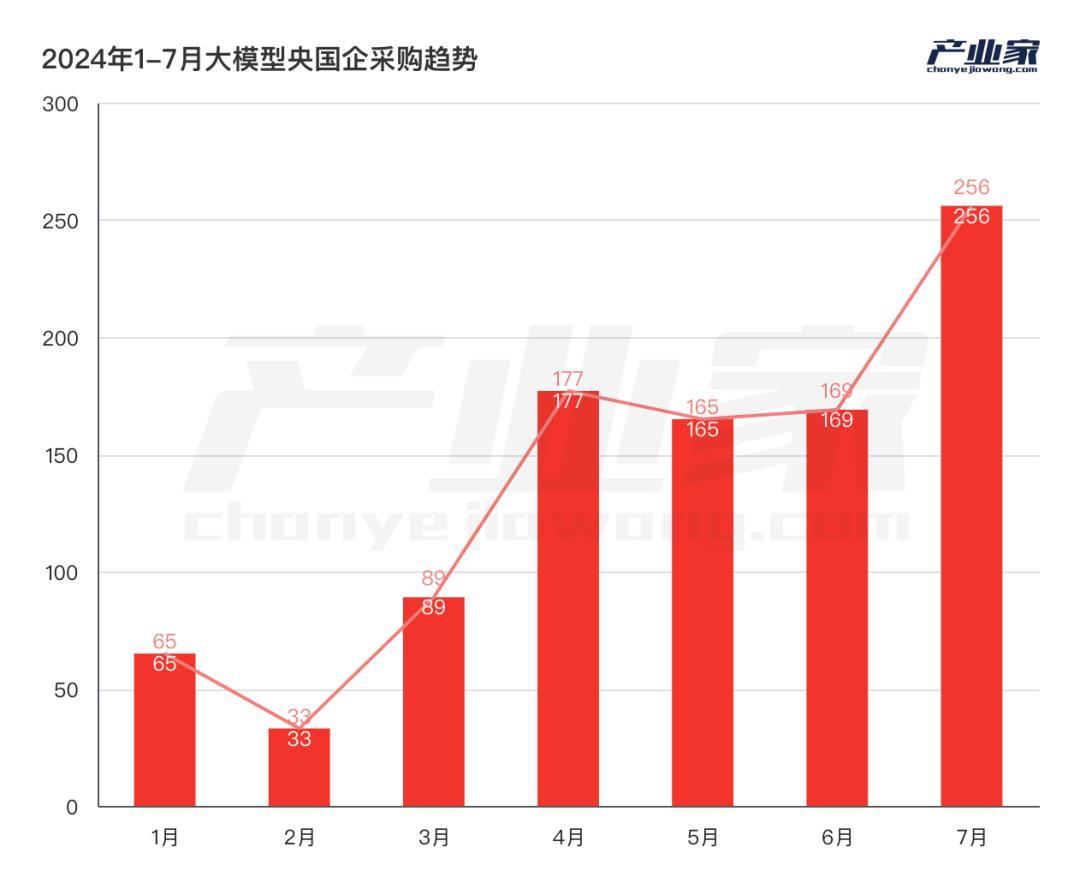
大模型紛紛落地國央企,陣勢如此浩蕩的背後,政策推動成為決定性因素。據沙丘智庫,自2023年以來,國資委多次對中央企業發展人工智慧提出要求。其中,在2024年2月的中央企業人工智慧專題推進會上,提出中央企業要“開展AI+專項行動”。會上就有10家央企簽署倡議書,表示將主動向社會開放人工智慧應用場景。
同年7月,國新辦舉行“推動高質量發展”系列主題新聞釋出會,提出未來五年,中央企業預計安排大規模裝置更新改造總投資超3萬億元,更新部署一批高技術、高效率、高可靠性的先進裝置。
政策的推動,當然是其中不可忽視的因素。但除了政策影響,站在產業數字化和數智化的潮頭,央國企紛紛落地大模型的背後還有哪些推動因素?一個更值得思考的問題是,和雲端計算時代金融行業成為先鋒官不同的是,在如今的AI大模型時代,為什麼央國企會成為先行力量?
一、運營商、政務、能源搶先建設智算中心
AI大模型史上最大專案,當屬“智算中心”。
預訓練成本的瘋狂上漲和推理需求的不斷攀升,都在讓智算中心成為必要。近日,OpenAI CEO Sam Altman在接受採訪時表示,“OpenAI在年內不會發布ChatGPT-5,目前公司專注於ChatGPT-o1的研發和運營。”
GPT-5為什麼不發了?原本預計推遲釋出的o1又為什麼提前登場?這背後的原因不由得引人深思,而訓練成本就是這其中的關鍵因素之一。
言歸正傳,國內對大模型的預訓練需求也愈加迫切。在加速構建國內AGI梯隊的同時,效能不斷重新整理的大模型需要大規模智算叢集的支撐。如今,萬卡叢集已然成為大模型軍備賽的標配。而除了國內AI企業和電信運營商,正在推動落地的央國企也在加速構建智算叢集,以提高AI大模型的訓練及推理效率。
通常來講,智算中心是由地方政府或電信運營商主導建設。據中國信通院不完全統計,截止2024年7月底,納入監測的智算中心(含已建和在建)已達87個。
2023年10月,瀋陽智慧計算中心新基建專案工程總承包(EPC)成交結果出爐,百度攜手中國建築第八工程局有限公司(中建八局)成功中標,中標金額為9.1億元。具體包括機房建設、機櫃設計、智算中心平臺,以及百度為其提供的AI軟硬體能力的綜合性解決方案。
而像這樣的智算中心採購專案,央國企已經開始了鋪天蓋地的建設。對此,產業家根據金額大小,列舉了近兩年央國企採購智算中心專案金額最高的10個。
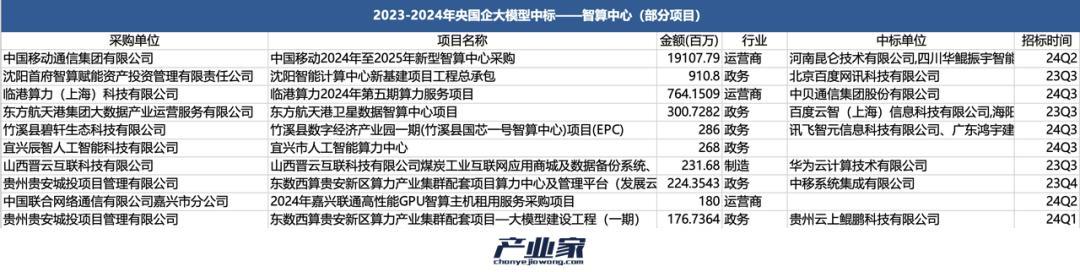
對比雲端計算時代,傳統資料中心的中標方大多都是IDC廠商;而在如今的AI時代,則多了不少AI企業和網際網路廠商的身影。
另外,從行業分佈來看,政務和運營商對智算中心的出資則更加大手筆。對此,產業家統計了運營商、能源和政務三大領域中智算中心專案的佔比:結果顯示,政務行業對智算中心的投入更大,其中包括GPU租賃、硬體以及算力排程平臺的採購。
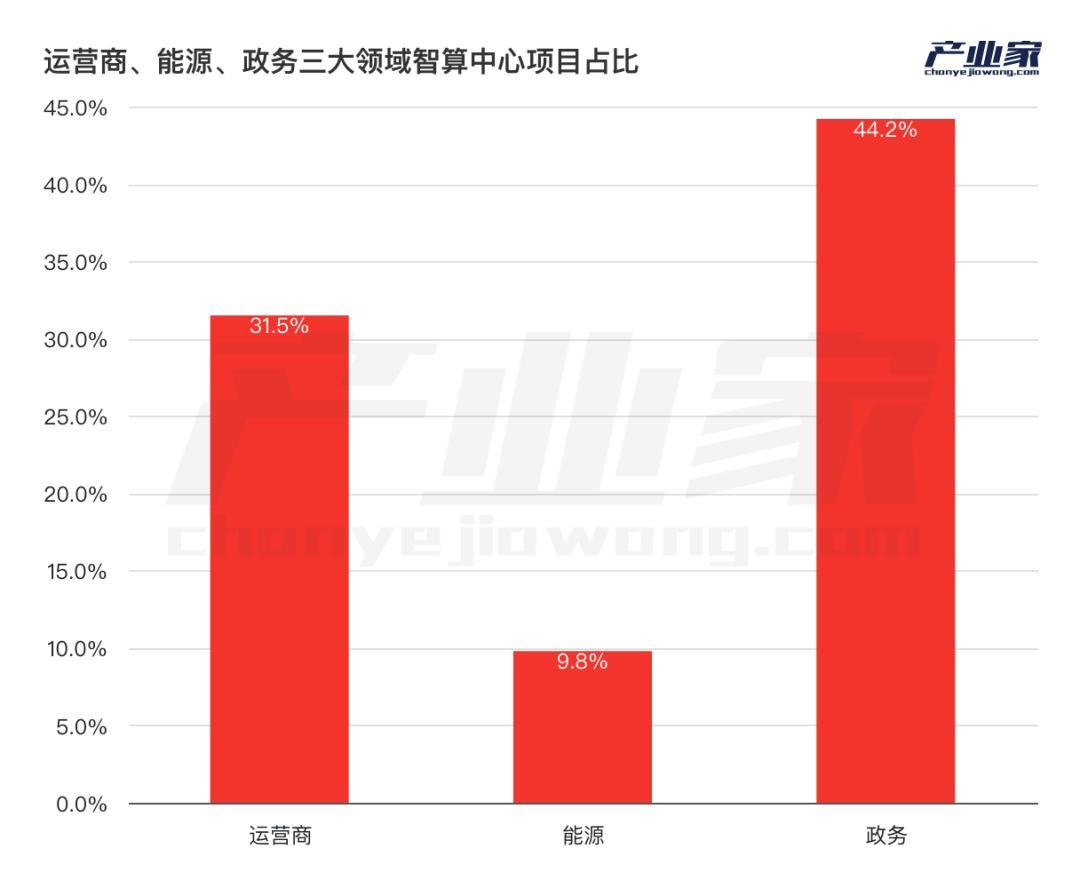
實際上,從智算中心投入比就可以看出央國企對AI大模型的需求。
可以看到的是,自2023年三季度,央國企就已經開始緊鑼密鼓地籌備智算中心建設。而智算中心只是央國企落地AI的一個起點。
一方面,這與上文提到的政策時間點正好吻合;另一方面,2023年第三季度也恰好是以百度、阿里、華為和電信運營商為首的“國內AGI梯隊”剛剛形成。
除了智算中心,央國企對AI大模型建設的另一個重點則是行業應用,即針對特定場景搭建大模型平臺或應用。
以電信運營商為例,據不完全統計,從2023年至今,運營商對AI大模型的專案建設達到了238起,其中除了75起智算中心建設外,剩餘都圍繞特定的場景構建大模型,主要有智慧客服、營銷和數字人方面的採購。
不同行業對於AI大模型的需求不同,專案重點自然也不一樣。對於政務和運營商行業而言,之所以智算中心佔比更大,除了政策推動,更重要的原因是對於私有化部署、本地部署的需求極高,尤其是政務領域;另一方面,相對於其他行業針對單點或各別環節的大模型應用開發,政務和運營商對大模型的需求則更為系統化,更需要從GPU資源到算力排程平臺來發揮作用。
相比之下,在應用AI大模型最多的三個行業中,能源領域對智算中心的投入較少,而更多圍繞大模型訓練和開發方面,尤其是針對特殊場景如何訓練並最佳化演算法,如何微調模型等等。
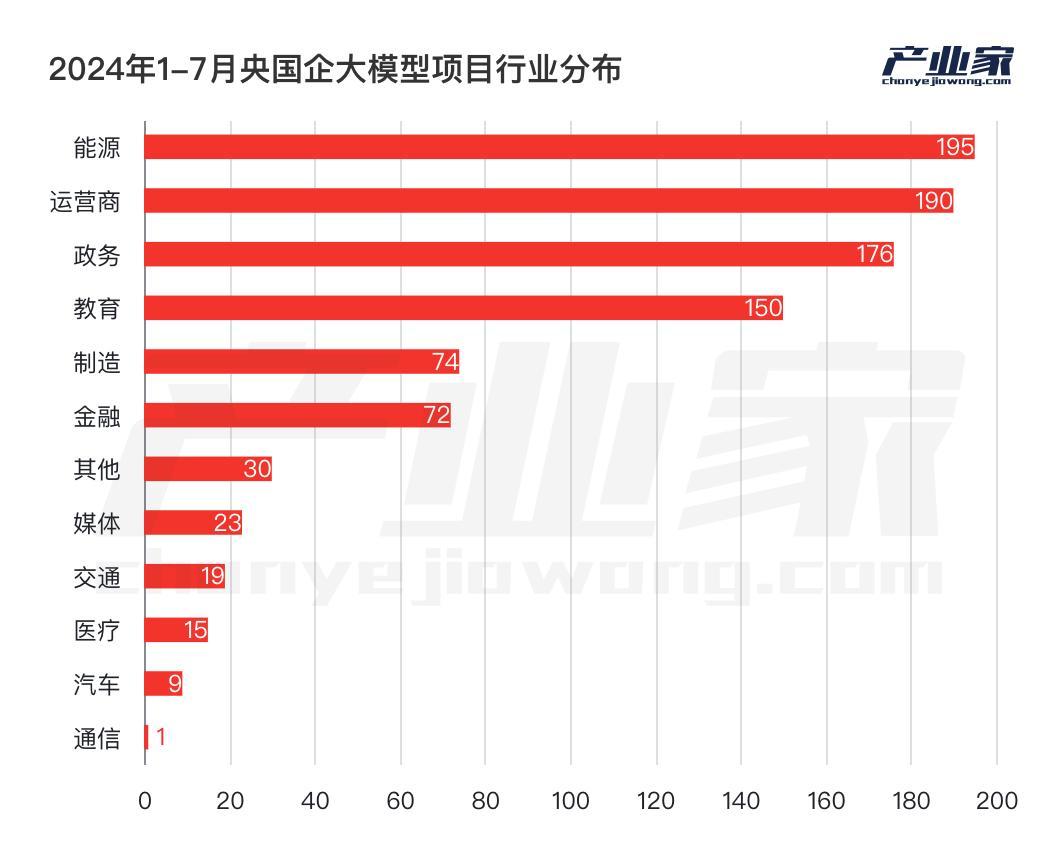
另外,值得注意的是,對於這些對行業know-how要求更高的領域而言,他們選擇中標方的時候也更為講究;比如在挑選算力排程平臺和大模型預訓練、開發階段時,中標方則圍繞以百度、科大訊飛為首的AI企業;而在選擇在大模型開發過程中,需要特定技術研究時,則會選擇南方電網這類更懂know-how的企業。
最後,不同於雲端計算時代,金融行業成為頭部落地試驗田;在如今的AI大模型時代,在央國企當中,有四大行業脫穎而出,分別是教育、能源、運營商、政務;而金融行業卻並沒有表現出像雲端計算時代那麼強的意願。
二、AI大模型:顛覆傳統IT架構背後
時代變遷。
在過去的雲端計算時代,大型企業進行數字化轉型需要從購買或租賃伺服器,到選址建資料中心,再到選擇合適的雲架構,接下來到平臺開發環節及上層應用的搭建。
通常來講,一家大型企業,如能源或工業企業來說,面對分佈在各環節的資料,通常需要建底層的PaaS平臺,從而實現靈活呼叫、互聯互通;但儘管如此,資料孤島、資料煙囪依然存在。
然而,這種從IaaS到PaaS再到SaaS的架構,在如今的AI大模型時代已經徹底被顛覆。企業往往需要一個行業大模型即可搞定,而不再會為了構建多個複雜應用,費時搭建PaaS平臺。
誠然,企業在雲端計算時代交得學費也並沒有浪費,在AI大模型時代,央國企在政策引導、需求迫使和環境因素等多方作用下已經開始先行落地AI大模型。
而在這其中,很大一部分都是基於過去雲端計算時代一些無法解決的頑疾,希望在AI大模型這裡找到更好的解法。
可以觀察到一個現象,目前央國企在大模型落地方面,主要圍繞兩點,一個是智算中心,一個是行業應用。後者包括大模型預訓練,大模型開發,以及針對各別環節或特定場景構建大模型應用或解決方案。
通常來說,後者透過大模型基於特定場景的解決方案,都是在過去雲端計算時代無法實現的。
以運營商為例,雖然智慧客服已經存在很多年,準確地說,自雲端計算時代以來,各類智慧客服軟體和解決方案層出不窮,然而對於整個行業來講,轉人工率依舊居高不下,普遍都在80%以上。而當時代的列車剛剛駛入大模型時代,智慧客服就成了大模型落地的第一塊試驗田。

再比如在能源行業,知識如何沉澱,再如何讓新人用起來,一直都是一大難題。即使在雲端計算時代,工業網際網路平臺林立,很多問題依舊沒有答案。而在如今的大模型時代,一個行業大模型便可以解決很多問題。這其中關鍵發揮作用的便是在行業大模型構建過程中的RAG搭建環節,它相當於一個企業知識庫,任何輸入的知識,都可以輕鬆呼叫。

像上述所展示的,對於某些行業來說,大模型並不是“雞肋”。相反,它能夠扮演“超強大腦”的角色,將企業的全部智慧匯聚到一起,並有的放矢地發揮作用。
然而,對有些行業而言,大模型目前還並未找到用武之地。
比如在金融行業,目前落地較多的專案主要圍繞知識庫問答方面,很難深入到核心業務。一方面,是出於金融監管和資料隱私等顧慮;另一方面,也是更重要的,目前AI幻覺問題還很難徹底得到解決,任何AI演算法可能為金融行業所帶來的錯誤預測和建議,都可能帶來重大經濟損失。
而無論是智慧客服還是行業大模型,無論是政務領域,還是運營商或能源、政務、教育等行業,在央國企先行落地大模型的背後,有三點核心原因。
首先,在大模型時代,央國企多年積累的資料得以發揮作用,他們不僅僅包括像財報報表、交易記錄等已經做好歸納整理的結構化資料,還包括一些重要的企業資產,如散落在各個系統內部的聊天記錄、檔案、圖片等等,如今這些非結構化資料都可以在AI大模型中,變成“企業知識庫”,併發揮其價值;
其次,不同於過去雲端計算時代從IaaS到PaaS再到SaaS的三層架構,大模型有著很強的協同性,只需在前期大模型開發階段做好訓練和微調,後期即可直接基於資料進行前端行為的加持。
最後,也是很重要的一點,央國企本身就有龐大的伺服器叢集,其自身具備強大的算力基礎,基於這些基礎可以更好地推進大模型落地。
三、競爭點:預訓練、安全及行業know-how
從中標情況來看,可以毫不誇張地說,央國企撐起了國內大模型商業化的半壁江山。
然而,大模型落地程序行至中途,仍然有很多問題亟待解決。
據中信建設證券資料顯示,2024年-2027年全球大模型推理的峰值算力需求量的年複合增長率為113%,遠高於訓練的78%。而預訓練成本和推理成本的疊加,也推升了整個AI基礎設施的市場份額。
據艾瑞諮詢推算,2023年中國AI基礎資料服務市場規模為45億元,預計到2028年,其市場規模將達170億元,且未來五年的複合增長率為30.4%。
這同時也解釋了近兩年央國企搶建智算中心的原因。然而,阻擋大模型落地程序的還不僅僅是算力資源短缺。
雖然大模型時代已經顛覆了過去從IaaS到PaaS再到SaaS的傳統三層架構,但在新時代下,新的架構也迎來了一些新的挑戰,比如從AI Infra到MaaS,再到上層的AI應用,中間涉及很多模型搭建的環節,這些都需要大模型服務商與企業一同探索落地路徑。
對於央國企來說,用AI大模型賦能雖然已成為共識,但怎麼用大模型,具體把大模型加在哪個環節,大模型如何發揮作用,以及如何開發和訓練大模型,面對這些問題,企業並沒有太多頭緒。因此,這就給AI大模型供應商提出了更高的要求。
在這過程中,供應商是否掌握行業know-how,在有些時候甚至可以成為能否拿下標的的關鍵因素。對此,以百度、華為、科大訊飛為首的AI大模型企業,都不約而同地在2024年扛起“行業大模型”的大旗。
據統計,在能源領域,2024年上半年就出現了不少預訓練過程中某項技術研究的投標專案。
另外,值得注意的是,隨著AI應用走向深水區,資料安全、資料共享和資料溯源等問題則開始被一一搬到檯面上。據悉,10月9日,中辦、國辦正式釋出《關於加快公共資料資源開發利用的意見》,提出到2025年,公共資料資源開發利用制度規則初步建立;到2030年,公共資料資源開發利用制度規則更加成熟,資源開發利用體系全面建成。
雖然如今的AI大模型已經可以讓資料溯源成為現實,但其中的責任劃分和資料安全等等問題,還需要AI服務商和企業一同探索。

2024-11-16 0 人在看

2024-11-16 0 人在看

2024-11-16 0 人在看
2024-11-16 0 人在看

2024-11-16 0 人在看
2024-11-15 0 人在看

2024-11-15 0 人在看

2024-11-15 0 人在看
歡迎來到貳閱資訊平台,這裏是壹個彙聚了娛樂風采、時尚潮流、健康生活、金融市場動態、體育激情、曆史深度、科技創新及IT前沿等多元化領域的綜合型文章站點。我們致力于打造壹個豐富多彩的信息世界,讓每壹位訪客都能在這裏找到屬于自己的興趣與熱情。







