2024-11-09 01:36:58 2
君可知,我們每天在網上的見聞,有多少是出自AI之手?

除了「注意看!這個男人叫小帥」讓人頭皮發麻,
真正的問題是,我們無法辨別哪些內容是AI生成的。
養大了這些擅長一本正經胡說八道的AI,人類面臨的麻煩也隨之而來。
(LLM:人與AI之間怎麼連最基本的信任都沒有了?)
子曰,解鈴還須繫鈴人。近日,谷歌DeepMind團隊發表的一項研究登上了Nature期刊的封面:

研究人員開發了一種名為SynthID-Text的水印方案,可應用於生產級別的LLM,跟蹤AI生成的文字內容,使其無所遁形。

論文地址:https://www.nature.com/articles/s41586-024-08025-4
一般來說,文字水印跟我們平時看到的圖片水印是不一樣的。
圖片可以採用明顯的防盜水印,或者為了不影響內容觀感而僅僅修改一些畫素,人眼發現不了。
但本文新增的水印想要隱形貌似不太容易。

為了不影響LLM生成文字的質量,SynthID-Text使用了一種新穎的取樣演算法(Tournament sampling)。
與現有方法相比,檢測率更高,並且能夠透過配置來平衡文字質量與水印的可檢測性。
怎麼證明文字質量不受影響?直接放到自家的Gemini和Gemini Advanced上實戰。
研究人員評估了實時互動的近2000萬個響應,使用者反饋正常。
SynthID-Text的實現僅僅修改了取樣程式,不影響LLM的訓練,同時在推理時的延遲也可以忽略不計。
另外,為了配合LLM的實際使用場景,研究者還將水印與推測取樣整合在一起,使之真正應用於生產系統。
大模型的指紋
下面跟小編一起來看下DeepMind的水印有何獨到之處。
識別AI生成的內容,目前有三種方法。
第一種方法是在LLM生成的時候留個底,這在成本和隱私方面都存在問題;
第二種方法是事後檢測,計算文字的統計特徵或者訓練AI分類器,執行成本很高,且限制在自己的資料域內;
而第三種就是加水印了,可以在文字生成前(訓練階段,資料驅動水印)、生成過程中、和生成後(基於編輯的水印)新增。
資料驅動水印需要使用特定短語觸發,基於編輯的水印一般是同義詞替換或插入特殊Unicode字元。這兩種方法都會在文字中留下明顯的偽影。
SynthID-Text 生成水印
本文的方法則是在生成過程中新增水印。
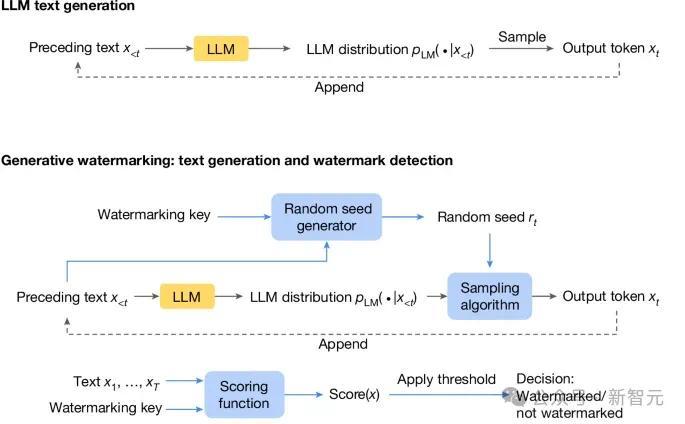
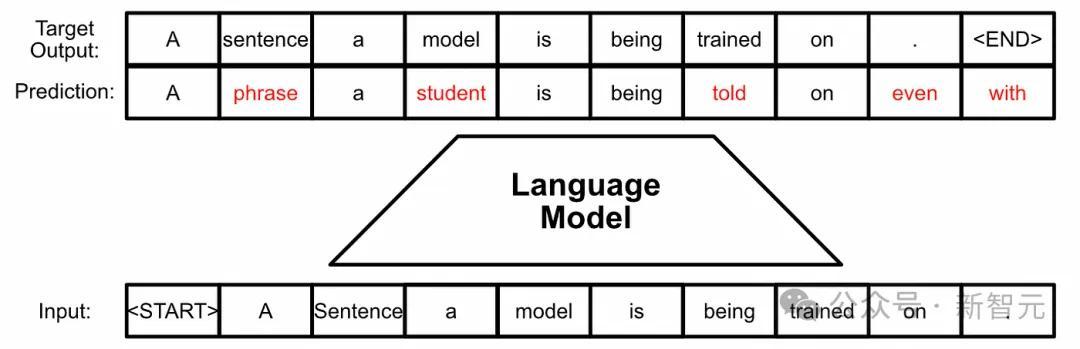
下圖是標準的LLM生成過程:根據之前的token計算當前時刻token的機率分佈,然後取樣輸出next token。

在此基礎之上,生成水印方案由三個新加入的元件組成(下圖藍色框):隨機種子生成器、取樣演算法和評分函式。
隨機種子生成器在每個生成步驟(t)上提供隨機種子 r(t)(基於之前的文字token以及水印key),取樣演算法使用 r(t) 從LLM生成的分佈中取樣下一個token。
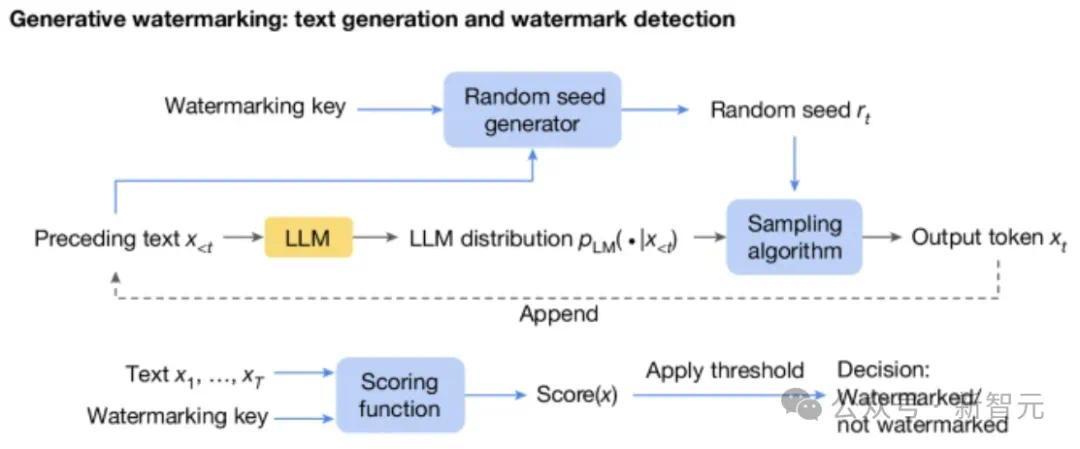
透過這種方式,取樣演算法把水印引入了next token中(即r(t)和x(t)的相關性),在檢測水印的時候,就使用Scoring函式來衡量這種相關性。
下面給出一個具體的例子:簡單來說就是拿水印key和前幾個token(這裡是4個),過一個雜湊函式,生成了m個向量,向量中的每個值對應一個可選的next token。

然後呢,透過打比賽的方式,從這些token中選出一個,也就是SynthID-Text使用的Tournament取樣演算法。
如下圖所示,拿2^m個token參加m輪比賽(這裡為8個token3輪比賽,token可重複),
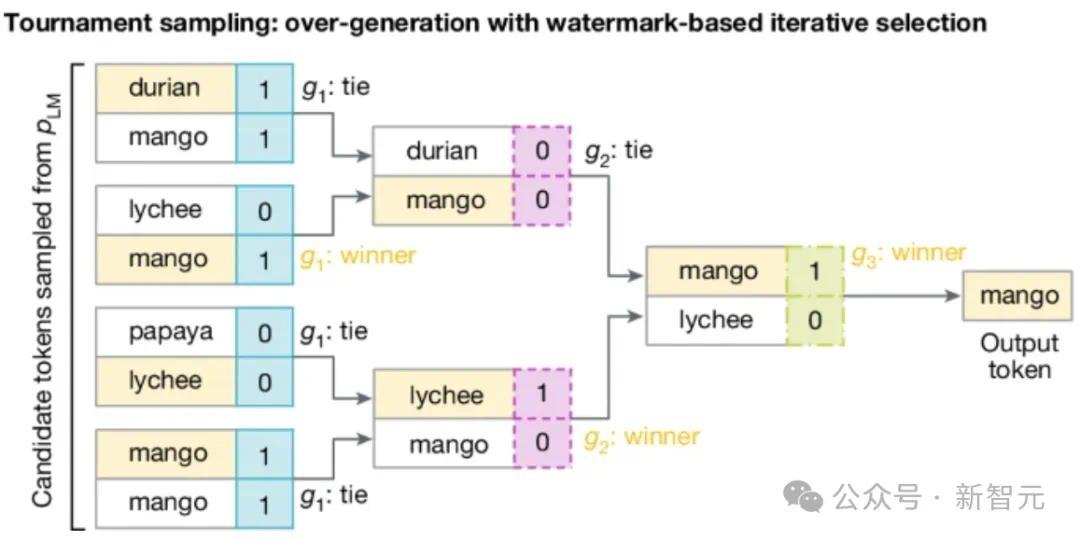
每輪中的token根據當前輪次對應的向量兩兩pk,勝者進入下一輪,如果打平,則隨機選一個勝者。
以下是演算法的虛擬碼:

水印檢測
根據上面的賽制,最終勝出的token更有可能在所有的隨機水印函式(g1,g2,...,gm)中取值更高,
所以可以使用下面的Scoring函式來檢測文字:
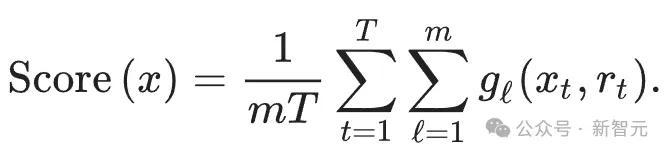
把所有的token扔進所有的水印函式中,最後計算平均值,則帶水印的文字通常應該得分高於無水印的文字。
由此可知,水印檢測是一個程度的問題。影響評分函式檢測效能的主要因素有兩個。
首先是文字的長度:較長的文字包含更多的水印證據,可以讓檢測有更多的統計確定性。
第二個因素是LLM本身的情況。如果LLM輸出分佈的熵非常低(意味著對相同的提示幾乎總是返回完全相同的響應),那麼錦標賽取樣(Tournament)無法選擇在g函式下得分更高的token。
此時,與其他生成水印的方案類似,對於熵較小的LLM,水印的效果會較差。
LLM本身的熵取決於以下幾個因素:
模型(更大或更高階的模型往往更確定,因此熵更低);
來自人類反饋的強化學習會減少熵(也稱為模式崩潰);
LLM的提示、溫度和其他解碼設定(比如top-k取樣設定)。
一般來說,增加比賽的輪數(m),可以提高方法的檢測效能,並降低Scoring函式的方差。
但是,可檢測性不會隨著層數的增加而無限增加。比賽的每一層都使用一些可用的熵來嵌入水印,水印強度會隨著層數的加深而逐漸減弱。本文透過實驗確定m=30。
文字質量
作者為非失真給出了由弱到強的明確定義:
最弱的版本是單token非失真,表示水印取樣演算法生成的token的平均分佈等於LLM原始輸出的分佈;
更強的版本將此定義擴充套件到一個或多個文字序列,確保平均而言,水印方案生成特定文字或文字序列的機率與原始輸出的分佈相同。
當Tournament取樣為每場比賽配置恰好兩個參賽者時,就是單token非失真的。而如果應用重複的上下文掩碼,則可以使一個或多個序列的方案不失真。
在本文的實驗中,作者將SynthID-Text配置為單序列非失真,這樣可以保持文字質量並提供良好的可檢測性,同時在一定程度上減少響應間的多樣性。
計算可擴充套件性
生成水印方案的計算成本通常較低,因為文字生成過程僅涉及對取樣層的修改。
對於Tournament取樣,在某些情況下,還可以使用向量化來實現更高效率,在實踐中,SynthID-Text引起的額外延遲可以忽略不計。
在大規模產品化系統中,文字生成過程通常比之前描述的簡單迴圈更復雜。
產品化系統通常使用speculative sampling來加速大模型的文字生成。
小編曾在將Llama訓練成Mamba的文章中,介紹過大模型的推測解碼過程。
簡單來說就是用原來的大模型蒸餾出一個小模型,小模型跑得快,先生成出一個序列,大模型再對這個序列進行驗證,由於kv cache的特性,發現不符合要求的token,可以精準回滾。
這樣的做法既保證了輸出的質量,又充分利用了顯示卡的計算能力,當然主要的目的是為了加速。
所以在實踐中,生成水印的方案需要與推測取樣相結合,才能真正應用於生產系統。
對此,研究人員提出了兩種帶有推測取樣演算法的生成水印。
一是高可檢測性水印推測取樣,保留了水印的可檢測性,但可能會降低推測取樣的效率(從而增加整體延遲)。
二是快速水印推測取樣,(當水印是單token非失真時)保留了推測取樣的效率,但可能會降低水印的可檢測性。
作者還提出了一個可學習的貝葉斯評分函式,以提高後一種方法的可檢測性。當速度在生產環境中很重要時,快速帶水印的推測取樣最有用。
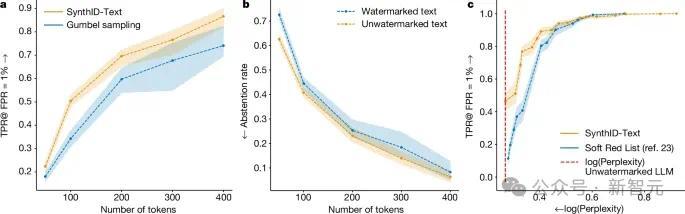
上圖表明,在非失真類別中,對於相同長度的文字,非失真SynthID-Text提供比Gumbel取樣更好的可檢測性。在較低熵的設定(如較低的溫度)下,SynthID-Text對Gumbel取樣的改進更大。

2024-08-31 48 人在看
2024-11-15 1 人在看

2024-11-15 1 人在看

2024-11-15 0 人在看

2024-11-14 0 人在看
2024-11-11 0 人在看

2024-11-11 0 人在看
2024-11-10 1 人在看
歡迎來到貳閱資訊平台,這裏是壹個彙聚了娛樂風采、時尚潮流、健康生活、金融市場動態、體育激情、曆史深度、科技創新及IT前沿等多元化領域的綜合型文章站點。我們致力于打造壹個豐富多彩的信息世界,讓每壹位訪客都能在這裏找到屬于自己的興趣與熱情。






